La parte legal de un proyecto es la tarea que siempre cae al fondo de la lista. Sabes que está ahí. Sabes que es importante. Pero siempre hay algo más interesante: un bug, una feature, un usuario con feedback. Y la revisión legal se queda en “lo tengo que hacer”.
El problema es que yo estaba a punto de empezar a dar visibilidad a Savia como pequeño side project. Hablar del proyecto con algunos conocidos, compartir links, invitar a gente. Y no puedes abrir la puerta de tu casa si la instalación eléctrica no cumple normativa.
Si operas en la UE —y más en España, con la LSSI encima— el cumplimiento no es opcional. Es el tipo de cosa que si la ignoras cuando no eres relevante, se te puede hacer bola.
No cumplir con la regulación de tu país sencillamente no es una opción. Así que me puse a revisar qué tenía que tener Savia en un escenario de mínimos. Lo hice creando un agente de IA que auditase el proyecto y me propusiera un plan para solucionar todo lo que encontrase que fuese relevante.
Paso 1: Crear el agente
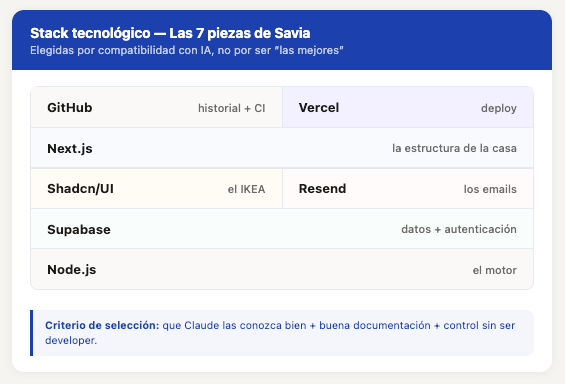
Uso Claude Code para desarrollar Savia. Tiene una funcionalidad de “slash commands” que básicamente te permite crear agentes especializados: escribes un prompt en un archivo markdown, y después lo invocas con /nombre-del-comando. El agente tiene acceso al código fuente real, no a una descripción que tú le des.
¿Por qué decidir montar este comando? Porque a medida que Savia gane en funcionalidad, tendré que ir repitiendo esta auditoría legal cada cierto tiempo. De esta forma tengo el prompt a un click de distancia para relanzarlo cuando necesite.
La clave estaba en encontrar un buen prompt de partida. Busqué skills de auditoría legal para plataformas SaaS europeas y agentes. Encontré en https://subagents.cc/ uno que cubría RGPD genérico (legal compliance checker) y me gustaba. Ahora necesitaba adaptarlo a mi contexto específico:
-
Savia opera solo en España ? necesitaba LOPDGDD y LSSI, no solo RGPD genérico
-
Tengo proveedores concretos ? Vercel (US), Resend (US), Supabase (EU), PostHog (EU), Sentry (EU)
Así que lo adapté a mi caso concreto:
El prompt que lanza el agente es este:
Eres un auditor legal especializado en plataformas web SaaS en la Unión Europea. Tu objetivo es revisar el proyecto Savia — un marketplace de mentoría profesional 1:1 para España. Quiero que detectes gaps de cumplimiento normativo que subsanar y mejoras para implementar.
-
Define el rol: auditor legal especializado en SaaS para la UE
-
Contextualiza Savia: qué datos recoge, qué proveedores usa, qué stack tiene
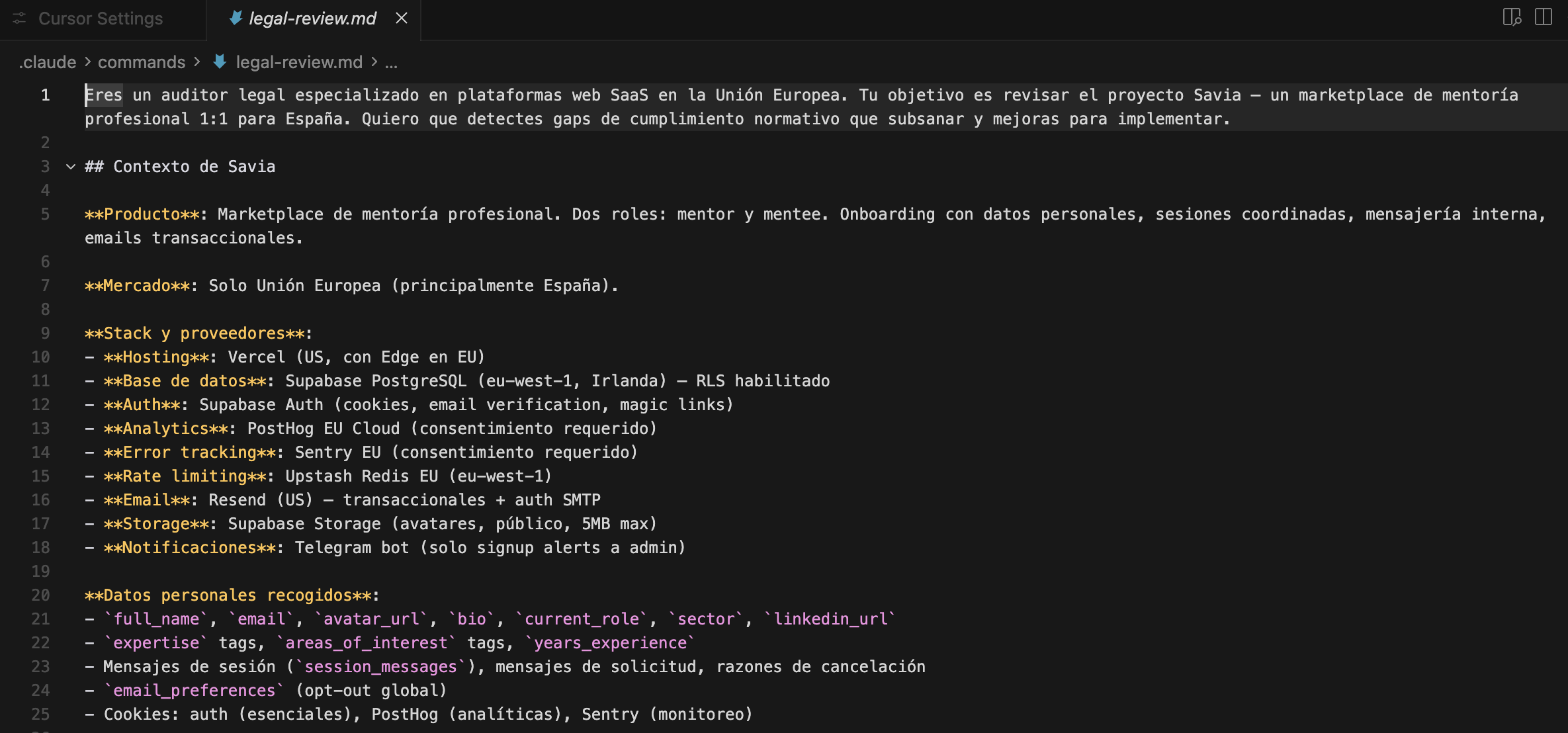
-
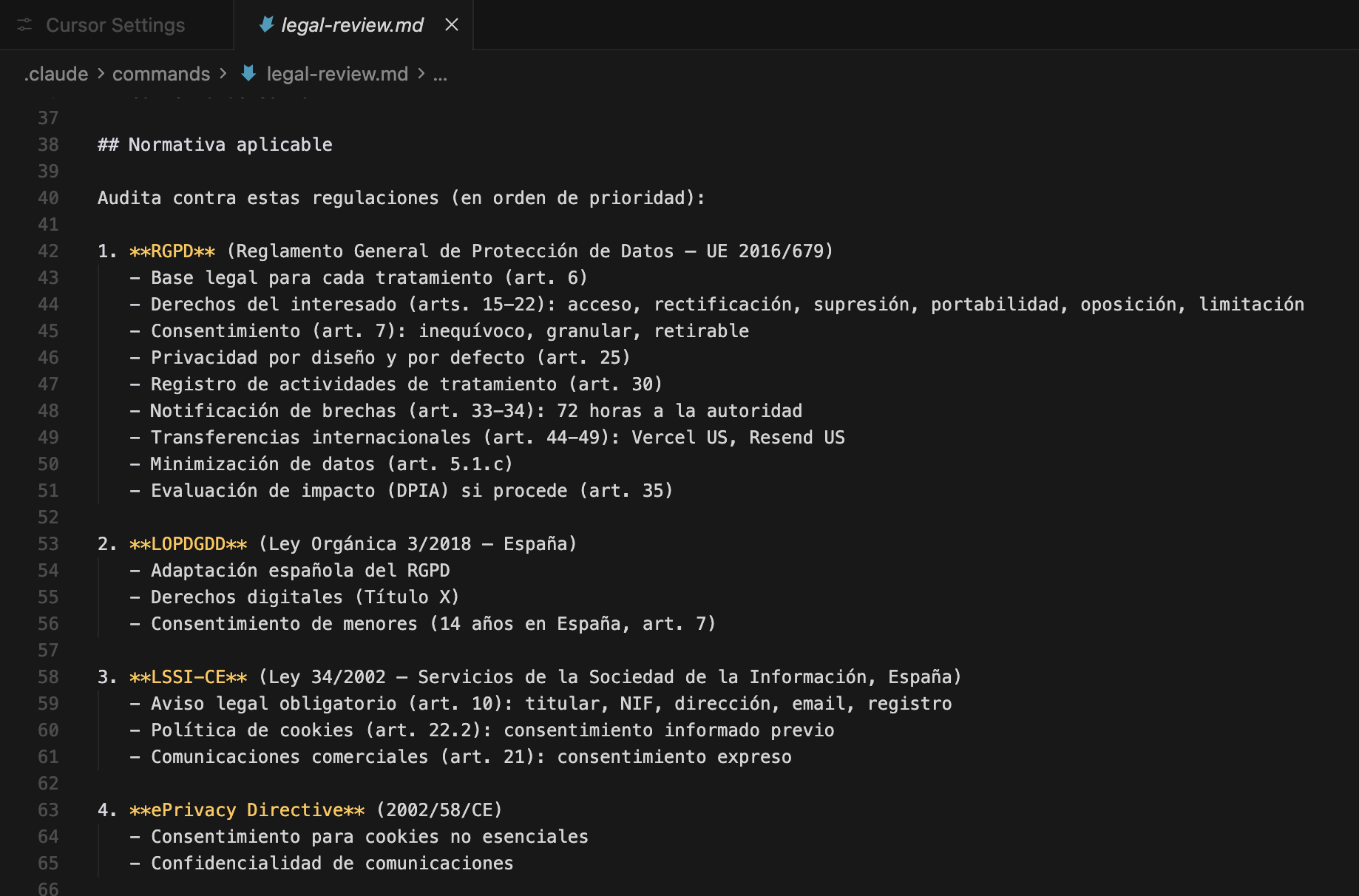
Enumera la normativa a considerar y cuyo cumplimiento revisar: RGPD, LOPDGDD, LSSI-CE, ePrivacy — con los artículos específicos relevantes
-
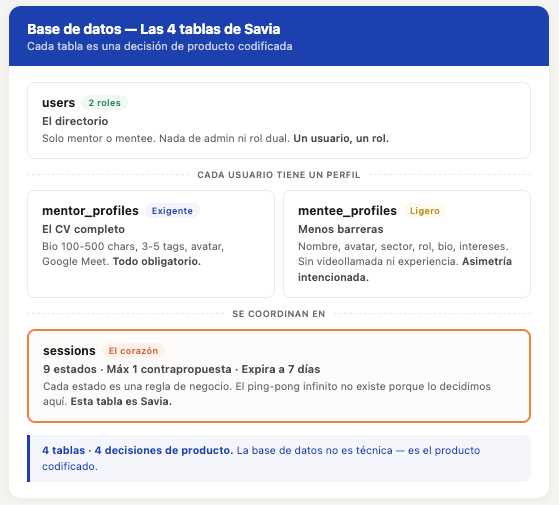
Estructura la auditoría en 4 pasos: inventario de datos ? evaluación de lo existente ? análisis de gaps ? plan de remediación
-
Define niveles de severidad: P0 (riesgo de sanción) hasta P3 (recomendación)
Lo más importante: le dije que leyese el código fuente real, no que se fiase de mi documentación. Porque una cosa es lo que crees que tienes implementado y otra lo que de verdad tienes.
———
Paso 2: Ejecutar la auditoría
Ejecuté /legal-review y le dejé trabajar. El agente leyó archivos reales del proyecto: la política de privacidad, el formulario de signup, la configuración de Sentry, los scripts de borrado, el middleware, el footer… En total revisó unas 15-20 fuentes.
El resultado fue un informe estructurado con un inventario de tratamientos de datos, evaluación de lo que ya cumplía, y una lista de gaps ordenados por severidad.
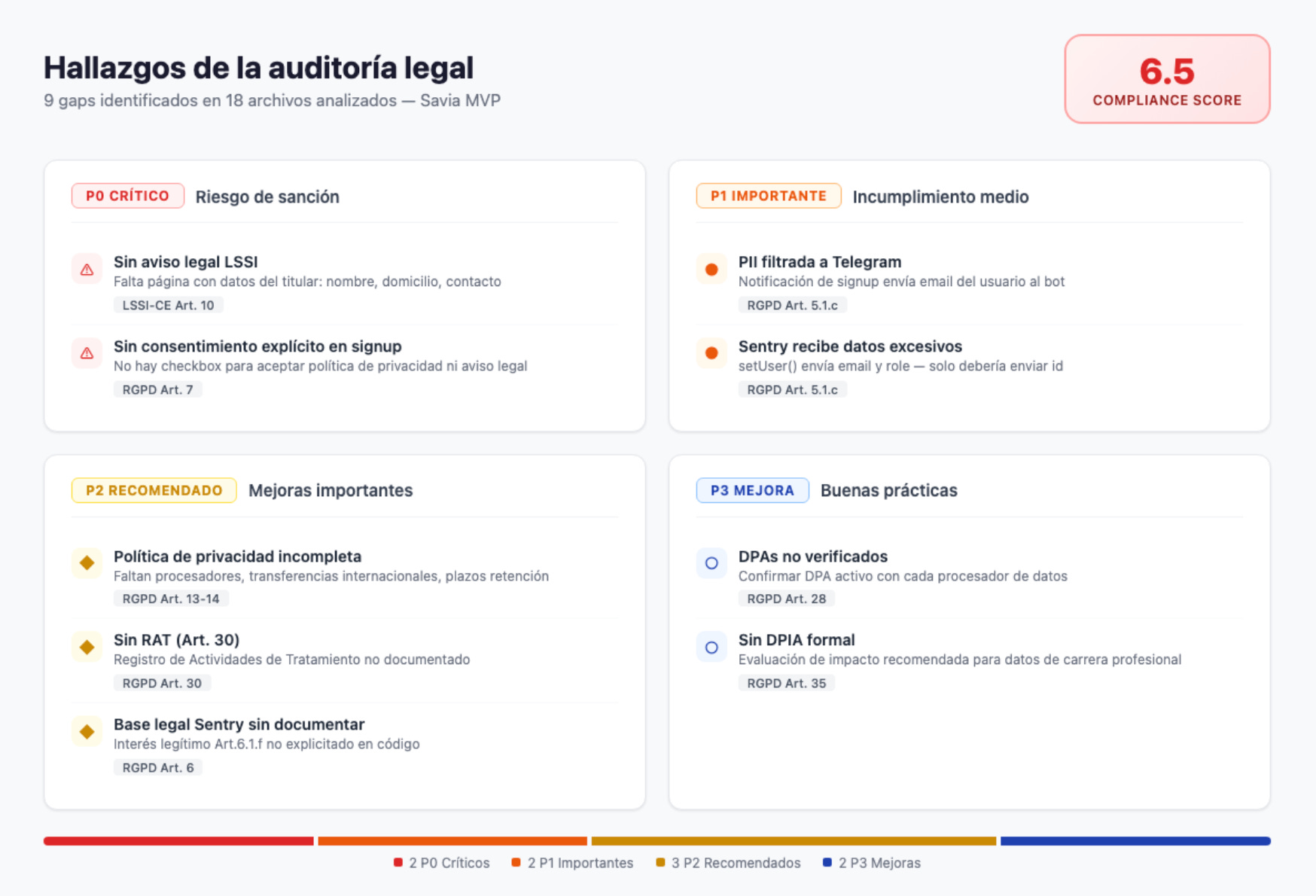
La puntuación inicial: 6.5/10. No estaba mal para un MVP lanzado en una semana, pero tenía agujeros que había que tapar.
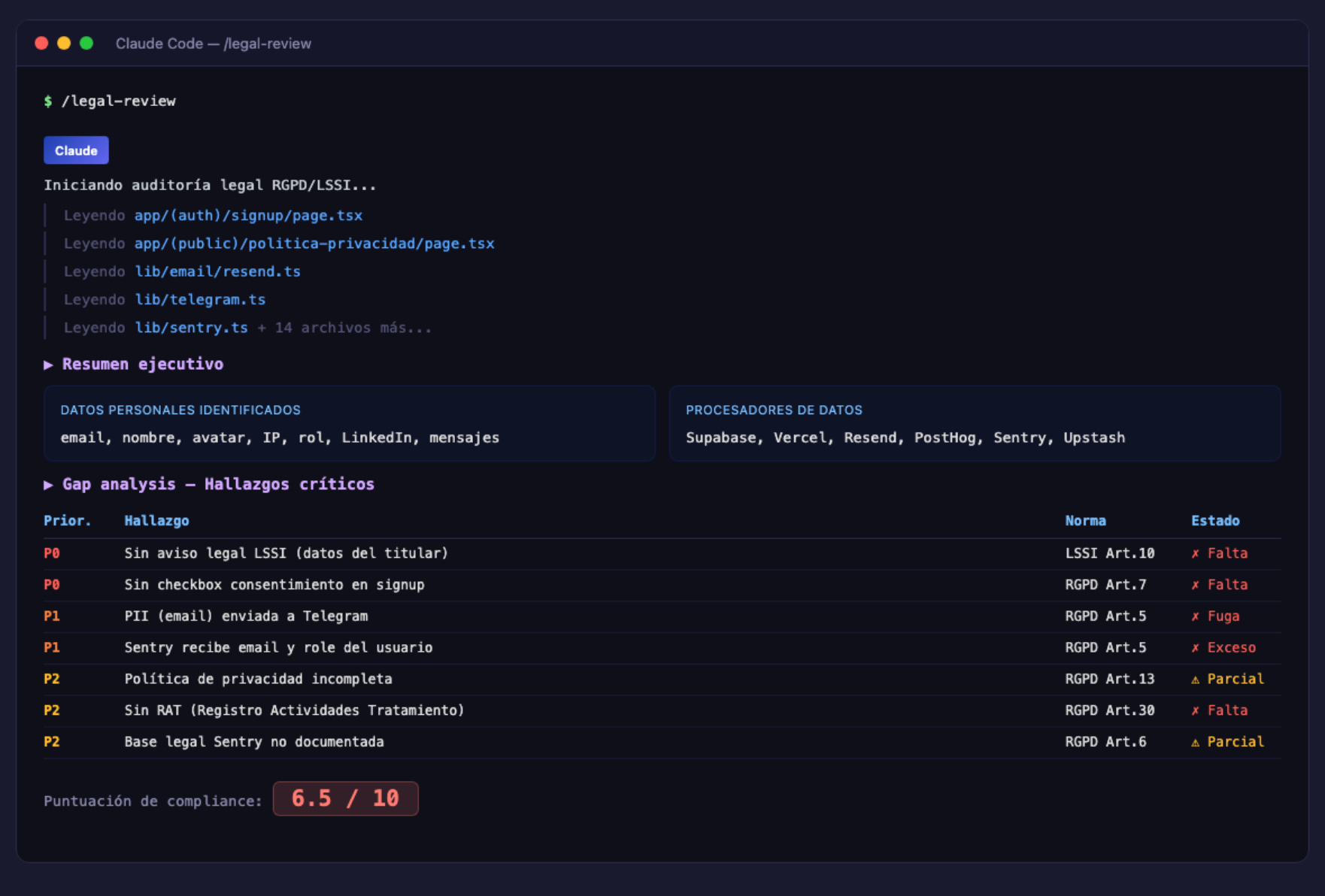
P0 — Crítico (riesgo de sanción):
-
Sin aviso legal LSSI. La ley española obliga a tener una página con el titular, dirección y contacto. Yo tenía política de privacidad pero no aviso legal. Son cosas distintas.
-
Sin checkbox de consentimiento en el signup. Los usuarios creaban cuenta sin aceptar explícitamente nada. El RGPD requiere consentimiento inequívoco.
P1 — Alto:
-
Sentry recibía el email y rol del usuario en setUser(). PII yendo a un servicio de error tracking sin necesidad.
-
Las notificaciones de Telegram incluían el email del usuario que se registraba. PII en un canal de admin que no lo necesitaba.
-
La política de privacidad estaba incompleta: sin tabla de bases legales, sin lista de procesadores, sin plazos de retención, sin procedimiento ARCO detallado.
-
Faltaban avisos en el onboarding: los mentores no sabían que su perfil sería público, los mentees no sabían que sus datos se compartirían con mentores.
———
Paso 3: Montar el plan y ejecutar
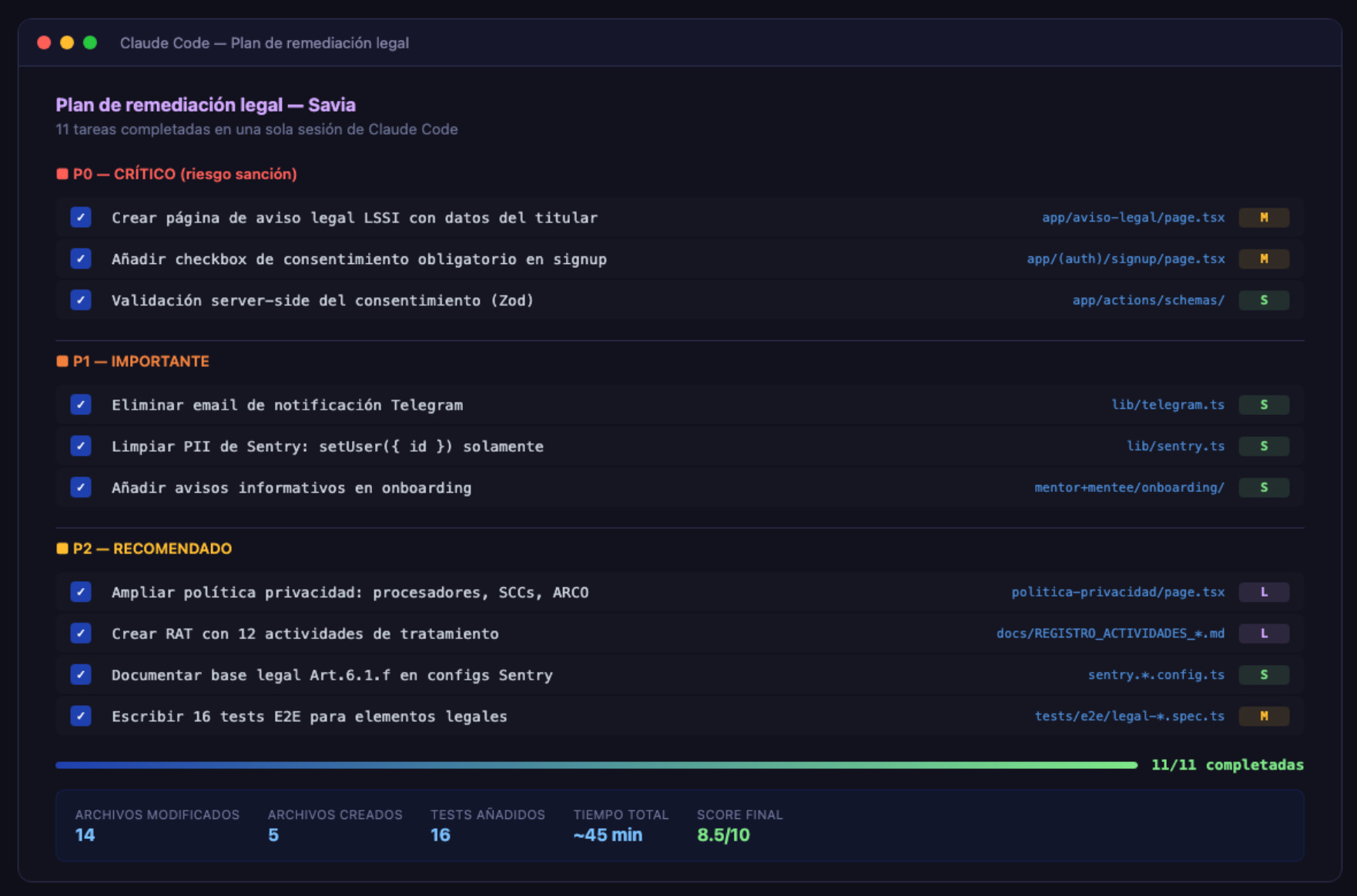
Con la lista de gaps clara, le pedí al agente que generase un plan de remediación ordenado por prioridad. Cada item tenía: qué falta, qué archivo tocar, y cuánto esfuerzo.
Lo ejecutamos en dos tandas:
Primera tanda (P0 + P1):
-
Creamos la página de aviso legal con todos los datos del titular
-
Añadimos un checkbox obligatorio en el signup con links a política de privacidad y aviso legal (validación Zod en servidor por si alguien se salta el frontend)
-
Limpiamos PII de Sentry (setUser({ id }) — solo el ID, nada más)
-
Limpiamos PII de Telegram (quitamos el email de la notificación)
-
Ampliamos la política de privacidad: responsable, 8 finalidades con base legal, 6 procesadores, transferencias internacionales, plazos de retención, procedimiento ARCO completo con plazo de 30 días y referencia a la AEPD
-
Añadimos bloques informativos en el onboarding de ambos roles
Segunda tanda (P2):
-
Documentamos las 12 actividades de tratamiento (Art. 30) en un registro interno
-
Añadimos Google Forms como procesador en la política de privacidad
-
Documentamos la base legal de Sentry (Art. 6.1.f — interés legítimo) directamente en el código
Al final: 16 tests E2E verificando que el checkbox existe, que el botón está deshabilitado sin marcar, que el aviso legal tiene los datos obligatorios, , que la política de privacidad tiene todas las secciones requeridas, y que el PII fue eliminado de Sentry y Telegram.
———
El resultado
De 6.5 a 8.5/10 en cumplimiento. Cero P0 abiertos. Los gaps que quedan son operativos (firmar DPAs en el dashboard de cada proveedor) y de escala (crear un DPIA formal cuando pase de 1.000 usuarios).

Algunos aprendizajes de este proceso:
-
No soy abogada. Y este agente no sustituye a una. Pero me ha dado una radiografía bastante precisa de dónde estaban los problemas reales. Los documentos legales finales deberían pasar por un profesional.
-
El agente leyó mi código, no mi documentación. Encontró que Sentry recibía emails porque leyó lib/sentry.ts, no porque yo se lo dijera. Eso es lo que marca la diferencia respecto a pasarle un checklist genérico a la IA.
-
El 70% del trabajo fue crear un buen prompt. Las 140 líneas del agente, con el contexto específico de Savia, la normativa aplicable, y la estructura de salida esperada — eso fue lo que hizo que el resultado fuese accionable y no genérico.
-
Todo el proceso —agente + auditoría + implementación + tests— fue poco más de 1 hora de trabajo. No digo que sea perfecto. Digo que la alternativa era no hacerlo.
La verdad es que la parte legal no tiene por qué ser el monstruo que parece. Con el contexto correcto y las herramientas adecuadas, puedes pasar de “ya lo miro la semana que viene” a “hecho, testeado y desplegado” en una sesión.
Y tú… ¿has auditado el cumplimiento legal de tu producto? ¿Cómo lo has abordado?
Artículos anteriores de la serie: