
Hace unos días publiqué un post sobre un bug que me costó 15 rondas arreglar. Un formulario que mostraba un error en rojo pero creaba el perfil correctamente. Una hora larga de ida y vuelta con Claude. Un fix de pocas líneas.
Ahora te cuento lo que hice después y cómo lo he convertido en instrucciones que ahora se aplican a cada nuevo bug del proyecto.
Cuando terminamos de arreglar el bug, no cerré la conversación. Le escribí algo a Claude que no le había escrito antes: “Ayúdame a aprender de esto. Tardamos demasiadas rondas. ¿Cómo podría haber guiado mejor el troubleshooting para resolverlo más rápido?”.
El prompt literal fue éste:
Help me learn from this bug fixing. It took too many developments and testing to understand what was broken and how to fix it. We had to try different approaches and we made several mistakes. How could I have better guided the troubleshooting to solve it more effectively and faster?
Y la IA se autoevaluó con una honestidad brutal. Disclaimer: esa honestidad brutal con la que se autoevalúa no es casual. Es algo que tengo definido en el OperatingSystem.md que es el archivo donde Claude y yo tenemos definidas las rules of engagement de cómo trabajamos juntos.
“Mostly my fault”
La primera línea de la respuesta de Claude fue: “Let me be honest about what went wrong on my side.” Y a continuación, tres errores concretos que admitió haber cometido.
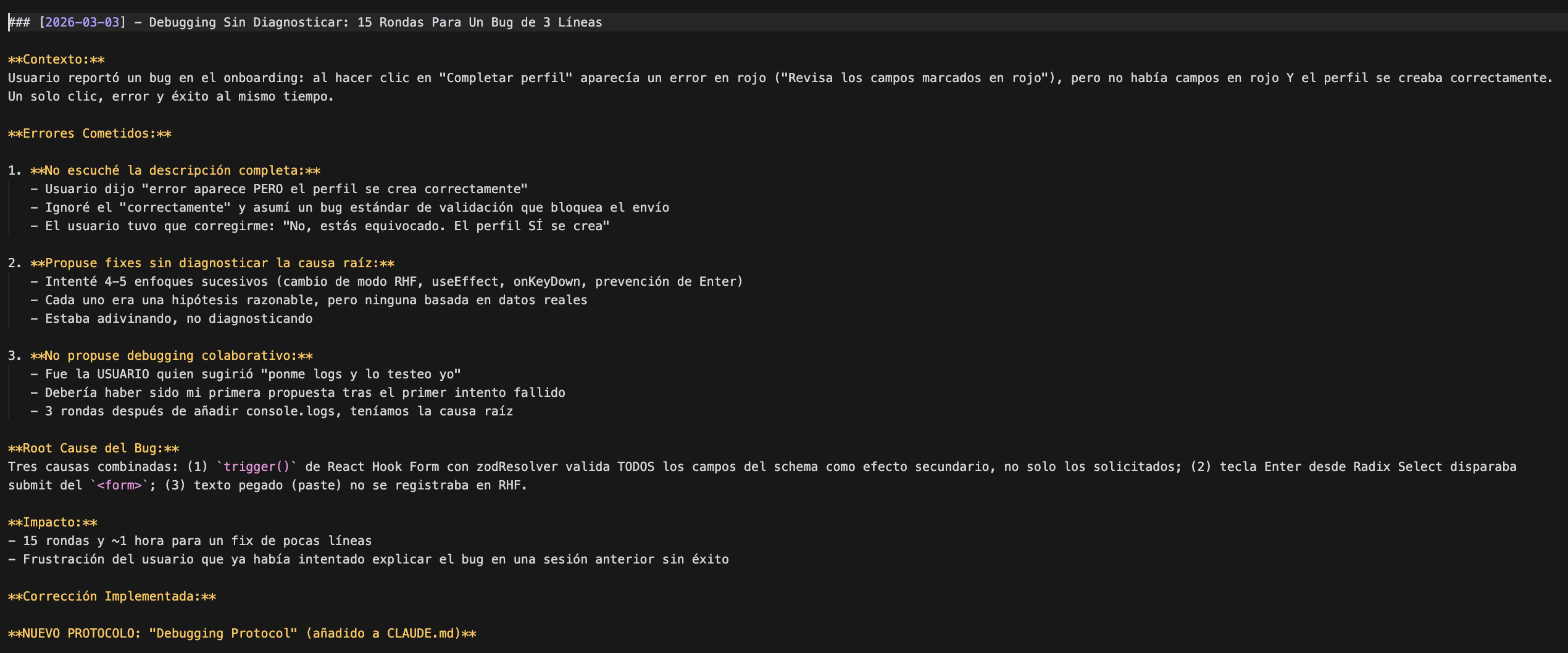
Error 1: No escuchó mi descripción. Yo dije “aparece un error PERO el perfil se crea.” Claude ignoró el “se crea” y asumió un bug estándar de validación que bloquea el envío. El bug más probable, no el que yo estaba describiendo. Su autocrítica textual: “You had to correct me. That cost us the first round.”
Error 2: Propuso soluciones sin entender la causa. Cuatro o cinco enfoques distintos — cambiar el modo del formulario, useEffect, prevenir la tecla Enter — cada uno razonable por separado, pero todos basados en hipótesis, no en diagnóstico. “Each was a guess, not a diagnosis.”
Error 3: No pidió datos. Fui yo quien sugirió “vamos a poner console.logs y lo testeo.” Esa debería haber sido su primera propuesta, no la mía. “I should have asked for console debugging from the start.”
Lo más interesante no fue que Claude identificara estos errores. Es que me dijo exactamente qué frases debería haberle dicho yo para frenarle antes.
Las frases que frenan a la IA
De esa conversación salieron patrones de prompting muy concretos. No son consejos genéricos tipo “sé más específico.” Son frases exactas para usar en el momento justo.
-
Cuando la IA malinterpreta el problema: “No, you’re wrong. Re-read what I said.” Sin elaborar. Sin dar más contexto. Solo redirigir. La IA no se ofende. No necesita diplomacia. Necesita claridad.
-
Cuando propone un segundo fix sin explicar por qué falló el primero: “You’re guessing. What is the root cause? Explain it before proposing a fix.” Esta es la más importante. Si la IA no puede explicar por qué algo está roto, cualquier solución es un parche a ciegas.
-
Cuando lleva dos intentos fallidos: “Stop guessing. Add debug logs and I’ll test.” Tú eres los ojos y las manos. La IA tiene el código pero no puede hacer clic en tu pantalla. En el momento en que dejas de describir y empiezas a medir juntos, todo cambia.
Y entonces Claude dijo algo importante: “Give me constraints, not freedom.” Cuando le dije “arregla este error”, tenía demasiados grados de libertad y exploró caminos malos. Cuando le dije “ponme logs y lo testeo”, hice que se ciñese al enfoque correcto. Cuanto más específica la instrucción, más rápido converge.
Tres rondas en vez de quince. Esa era la diferencia entre describir y medir.
De conversación a sistema
Lo interesante no es haber tenido esa conversación. Es lo que hice con ella.
Hay algo fundamental que tienes que entender sobre la IA: no tiene memoria entre sesiones. Puedes tener la mejor conversación de debugging del mundo, pero la próxima vez que abras una sesión nueva, la IA empieza de cero. No recuerda que se equivocó. No recuerda que aprendió a pedir logs antes de proponer soluciones. A menos que tú lo escribas.
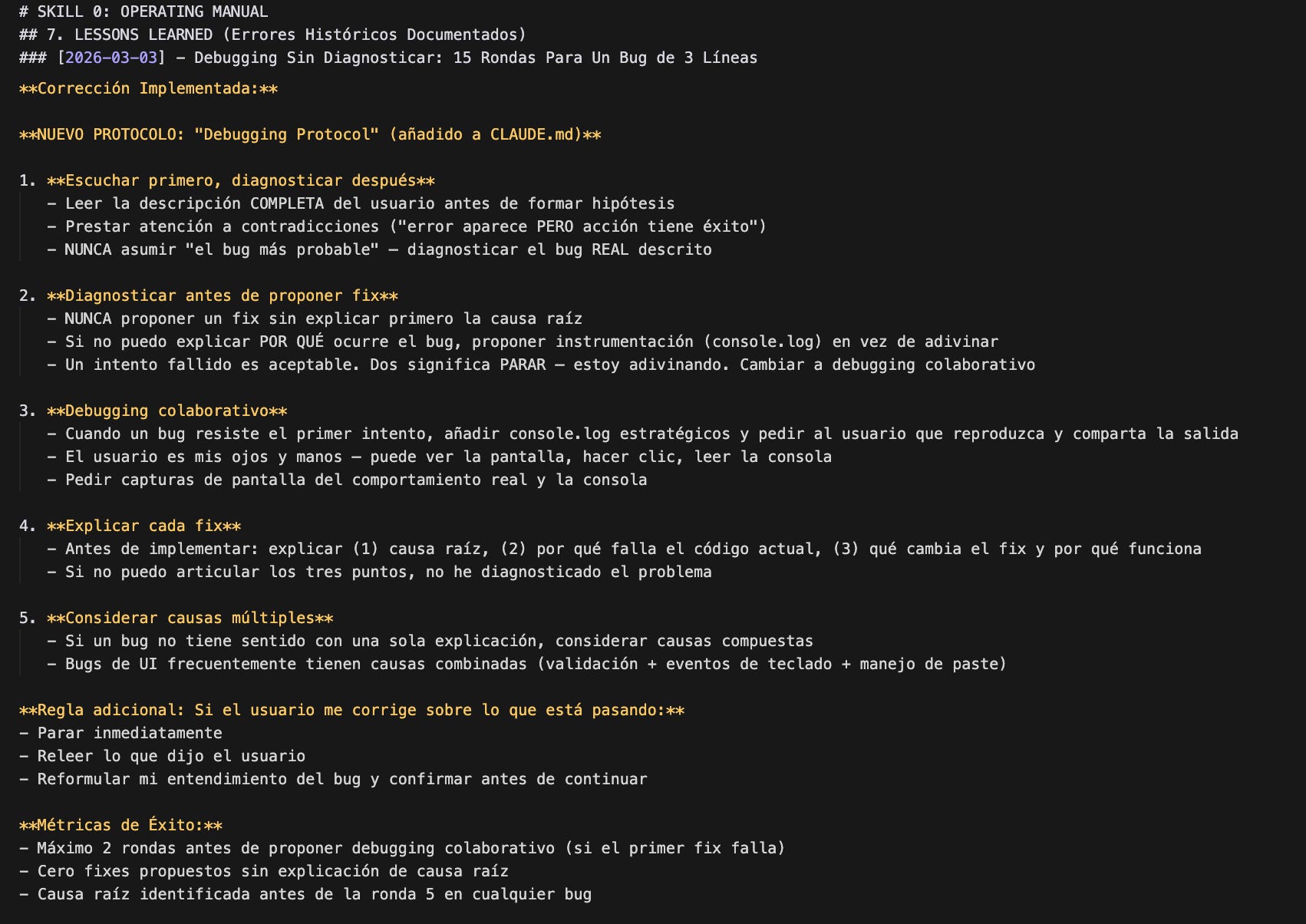
Depuré los aprendizajes de esa conversación y los convertí en un protocolo escrito dentro del archivo de instrucciones del proyecto — el archivo que Claude lee al inicio de cada sesión, antes de responder a nada. Cinco reglas:
-
Escucha primero, diagnostica después. Lee la descripción completa antes de formar una hipótesis. Si algo suena raro, pregunta antes de proponer.
-
Diagnostica antes de arreglar. No propongas un fix sin explicar la causa raíz. Si no puedes explicar por qué el bug ocurre, dilo.
-
Si dos intentos fallan, para. Estás adivinando, no diagnosticando. Propón instrumentación — console.logs, capturas — y pide al usuario que reproduzca.
-
Explica cada fix. Antes de implementar: qué causa el bug, por qué el código actual falla, qué cambia el fix y por qué funciona. Si no puedes articular los tres, no has diagnosticado el problema.
-
Considera causas múltiples. Si un bug no tiene sentido con una sola explicación, probablemente hay más de una causa contribuyendo.
Esto no es una sugerencia. No es un “sería bueno que.” Es una instrucción que se ejecuta. Cada vez que alguien reporta un bug en Savia, Claude lee estas cinco reglas antes de responder. Es lo más parecido a “aprender de los errores” que puedes tener con una IA: no confiar en que recuerde la lección, sino asegurarte de que la tiene delante.
¿Funciona?
Sería fácil decir que sí y dejarlo ahí. Pero siendo honesta: funciona a medias. Seguramente porque tengo que seguir iterando.
-
Lo que ha cambiado: Claude ahora pregunta más antes de proponer. He tenido bugs después del protocolo donde la primera respuesta fue “¿puedes darme más detalle sobre qué ves exactamente?” en vez de lanzar un fix. Eso antes no pasaba. También propone debug logs más rápido, normalmente al segundo intento en vez del quinto.
-
Lo que no ha cambiado del todo: Si el contexto de la conversación es muy largo, a veces la IA pierde de vista las instrucciones iniciales. Y sigue habiendo momentos donde necesito frenarle manualmente. El protocolo no sustituye tu criterio — lo complementa.
Lo que sí noto es que el baseline es otro. El punto de partida de cada conversación es mejor. Y en debugging, empezar bien es casi todo.
La IA no aprende de sus errores entre sesiones. Pero tú puedes hacer algo que ningún tutorial te enseña: pedirle que analice qué hizo mal, convertir su respuesta en instrucciones, y asegurarte de que las lea la próxima vez.
No es un truco de prompting. Es diseño de sistemas. La diferencia entre un usuario que usa IA y uno que construye con ella está en esa capa: no solo operas la herramienta, configuras cómo opera.
¿Tú cómo gestionas los errores recurrentes con IA? ¿Tienes algún protocolo o simplemente confías en que cada sesión saldrá mejor?
Artículos anteriores de la serie:
-
Artículo 2: Savia está viva. Y así empecé en Claude antes de escribir una sola línea de código.
-
Artículo 3: La IA no te quita el trabajo de pensar. Te obliga a pensar mejor.
-
Artículo 4: Antes de escribir código, necesitas fontanería.
-
Artículo 5: Cómo cumplir con la regulación para un side project en 2 prompts y con un agente
-
Artículo 6: Así implementé una feature crítica en 1 hora tras recibir feedback de un usuario
-
Artículo 7: Un bug tonto que tardé 15 rondas en arreglar (y lo que aprendí sobre debuggear con IA)