
Pero “construir” no empieza con la primera pantalla. Empieza con algo mucho menos glamuroso que va en paralelo: instalar cosas, conectar servicios, configurar credenciales.
Cosas que haces mientras empiezas a levantar las primeras pantallas, no antes. Es como reformar una casa. Antes de elegir los azulejos del baño, necesitas saber dónde van las tuberías. Nadie presume del desagüe en Instagram, pero sin él no funciona nada.
Este post va de eso. De las tuberías.
El stack como decisión de producto
Cuando montas un proyecto de software, una de las primeras cosas es elegir tu “stack”: las herramientas y tecnologías sobre las que vas a construir todo. Es una decisión que parece puramente técnica, pero es también de producto. Porque una vez que eliges, cambiar es carísimo.
Para Savía, yo no elegí las herramientas porque fueran “las mejores”. Las elegí porque Claude las conoce bien, tienen buena documentación, y me permiten mantener el control sin tener conocimientos de desarrollo.
Cuando tu equipo técnico es una IA, el criterio de selección cambia. No es “qué tecnología es superior”. Es “con qué puedo avanzar sin quedarme bloqueada cada dos horas”.
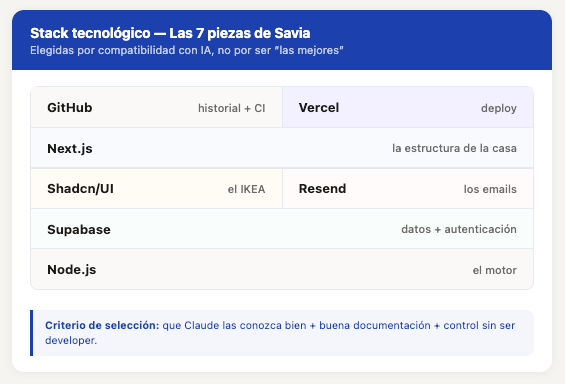
Estas son las siete piezas de Savia, en el orden en que las fui montando (aunque obviamente no fue un proceso 100% lineal).
-
Node.js — el motor. Es lo que permite ejecutar JavaScript fuera del navegador. Lo primero que instalas, como echar gasolina antes de arrancar el coche. Cinco minutos con Homebrew y listo.
-
Next.js — el framework. La estructura de la casa: paredes, techos, distribución de habitaciones. Viene con TypeScript, Tailwind CSS y un montón de convenciones que te ahorran decidir cosas. Un comando (npx create-next-app) y tienes un proyecto funcionando.
-
Shadcn/UI — los componentes prefabricados. Botones, formularios, tarjetas, menús. En vez de diseñar cada pieza desde cero, coges las que necesitas y las adaptas. El IKEA del diseño web.
-
Supabase — la base de datos en la nube. Donde viven los usuarios, los perfiles, las sesiones. También gestiona la autenticación: que la gente pueda registrarse y hacer login. Todo en un servicio. Disclaimer: es uno de los servicios que he tenido que invertir más tiempo en entender. Con futuras decisiones y cambios, tendré que pasar por aquí para ejecutar queries imprescindibles para aplicar esos cambios.
-
Resend — el servicio de emails. Que tu app pueda hablar con los usuarios: confirmación de registro, notificaciones de nuevas sesiones, recordatorios. Sin esto, tu producto es mudo. Disclaimer: este servicio que parecía relativamente sencillo es uno de los que más quebraderos de cabeza me acabó dando.
-
GitHub — donde vive el código. Cada cambio queda registrado, como un historial médico del proyecto. Si algo se rompe, puedes volver al estado anterior. Y tiene una cosa que no esperaba necesitar tan pronto: un pipeline automático que, cada vez que subes código, ejecuta verificaciones antes de que llegue a producción. Un vigilante que no duerme.
-
Vercel — donde vive el proyecto en internet. Conectas tu código, le das a un botón, y tu producto está online. Cada vez que haces un cambio, se despliega automáticamente. Disclaimer: un sitio amado y odiado a la vez. Si el deploy va bien, lo amas. Si el deploy falla y no entiendes por qué, lo odias.
Distintas piezas que forman un stack que una persona no técnica puede operar con ayuda de IA. Y eso, para mí, era el criterio que importaba.
Tu base de datos es tu producto
De todo lo anterior, hubo una parte que fue la que más “miedo” me daba: diseñar la base de datos. ¿Por qué? Porque cada tabla, cada columna, cada restricción es una decisión de negocio codificada.
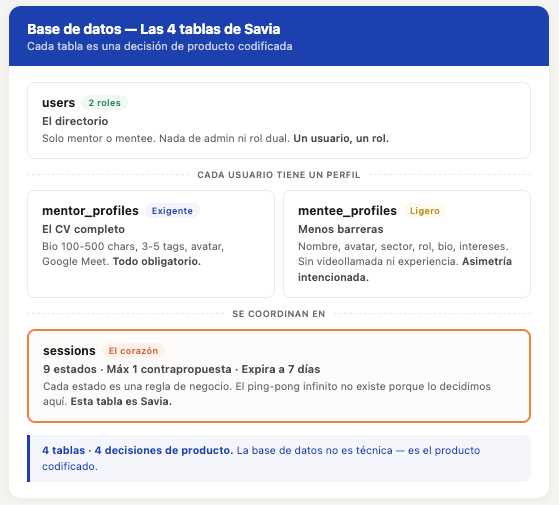
Savia tiene cuatro tablas. Así las pensamos:
users — El directorio. Solo dos roles posibles: mentor o mentee. Nada de “admin”, “superusuario” ni “rol dual”. Decisión consciente de simplificar. Un usuario, un rol. Nada más. Disclaimer: se que habrá que cambiar esto en algún momento. Hay desde el inicio feedback de usuarios que quieren tener rol doble y poder mentorizar y ser mentorizados a la vez. Lo he dejado fuera por ahora para no complicar demasiado la estructura de partida. Es muy posible que más adelante vea que fue un error y que migrar todo sea complejo.
mentor_profiles — El perfil exigente. Bio obligatoria de 100 a 500 caracteres. Entre 3 y 5 tags de áreas de experiencia. Avatar obligatorio. Enlace a LinkedIn obligatorio. Cada restricción es una decisión de producto: si los perfiles de mentores están incompletos, no generarán interés.
mentee_profiles — El perfil más ligero. Nombre, avatar, sector, rol, bio y áreas de interés. Sin años de experiencia, sin disponibilidad. Menos barreras, pero lo suficiente para que el mentor sepa con quién habla.
sessions — El corazón. Esta tabla tiene 9 estados posibles. Nueve. Porque el flujo de coordinación entre mentor y mentee es complejo: solicitud pendiente, aceptada, propuesta de fecha, contrapropuesta (máximo una), confirmada, completada, cancelada, expirada… Cada estado es una regla de negocio. Que solo puedas hacer tres contrapropuestas es una decisión para evitar el ping-pong infinito. Que una sesión expire a los 7 días sin actividad es una decisión para mantener el sistema limpio.
Para que estas tablas existan en la base de datos de verdad, se usan “migraciones”: archivos SQL que describen exactamente qué crear, como un plano arquitectónico. No tocas la base de datos a mano. Escribes el plano, lo ejecutas, y queda registrado. Si mañana algo se rompe, tienes el historial completo de qué se cambió y cuándo.
Créeme, le di vueltas. Muchas vueltas. Y no fue un proceso limpio: mientras definíamos tablas, ya estábamos levantando las primeras pantallas de onboarding. Las cosas no van en orden perfecto. Pero todo el trabajo de discovery de los posts anteriores — los flujos, las prioridades, las reglas de negocio — iba cobrando sentido a medida que tomábamos estas decisiones. Sin esa base, estas tablas habrían sido un caos.
Lo que nadie ve pero sostiene todo
Hay una última categoría de cosas que tuve que configurar: las tuberías invisibles. Variables de entorno, credenciales, conexiones entre servicios.
Las variables de entorno son, básicamente, las llaves de tu casa. Contraseñas, tokens, URLs que conectan tu app con Supabase, con Resend, con todo lo demás. Viven en un archivo que nunca se sube al código público (.env.local). Si lo pierdes, nada funciona. Si lo compartes, cualquiera tiene acceso a todo.
No es glamuroso. No es interesante de contar. Pero son decisiones que tomas una vez y condicionan meses de desarrollo. Como elegir el diámetro de las tuberías de tu casa: nadie lo ve, nadie te lo pregunta, pero si lo haces mal, lo pagas cada día.
Tres posts pensando. Uno montando tuberías. Y mientras tanto, las primeras pantallas ya iban tomando forma.
En la realidad, nada va en orden perfecto. Instalas Node.js, levantas una pantalla, te das cuenta de que necesitas Resend, vuelves a configurar cosas, sigues construyendo. Pero quiero documentar estas capas por separado porque la narrativa del “vibe coding” suele empezar por el final: alguien enseña una app funcionando y dice “lo hice con IA en un fin de semana”. Lo que no te cuenta son las decisiones que hicieron posible que ese fin de semana funcionara.
Vibe coding no es decirle a la IA “hazme una app”. Es tener tan claro lo que quieres que, cuando le pidas código, ese código tenga sentido.
Artículos anteriores de la serie: